Resumen
AI Act europeo desde 2025. En esta guía en español aprenderás qué es, cómo funciona su arquitectura (orquestador Opus, subagentes Sonnet y CitationAgent), qué limitaciones técnicas y económicas presenta y cómo aplicarlo con el Método JL.
El objetivo: darte una visión práctica con comparativas, checklist y casos reales para decidir si merece la pena en tu contexto.
Mini-brief ejecutivo
Claude Research surge como respuesta a la crisis de transparencia en IA. Su diseño multi-agente supera en un 90,2% el rendimiento de agentes únicos, pero con un coste operativo muy superior (15–26×). Cada sesión está limitada a 45 minutos, con ventanas de 200K–1M tokens y un CitationAgent que obliga a documentar todas las afirmaciones.
La ventaja estratégica: en agosto de 2025 entra en vigor el AI Act europeo, que exige trazabilidad y documentación técnica completa para sistemas de alto riesgo, con sanciones de hasta €35 millones o 7% de la facturación global. Claude Research está diseñado para cumplir estos requisitos de forma nativa.
En mercados hispanohablantes, con un crecimiento proyectado del 22,9% anual hasta 2033, esto supone una ventaja competitiva clara en sectores críticos como fintech, compliance regulatorio y educación superior.
El Método JL ofrece un marco para aplicar Claude Research de forma eficiente: definir objetivos SMART, dividir en ≤7 subtareas, aplicar regla [SIN CITA] y validar con un checklist de calidad. Así se evita caer en errores comunes como bucles infinitos, alucinaciones SQL o thin content.
Decisión recomendada: utilizar Claude Research en proyectos donde la profundidad y la auditabilidad justifiquen el coste —compliance, benchmarking o educación avanzada— y apoyarse en el Método JL para maximizar control y eficiencia.
Tabla comparativa inicial
| Dimensión | Claude Research | ChatGPT ADA | Gemini Deep Research | Perplexity Pro |
| Arquitectura | Multi-agente (Opus + Sonnet + Citation) | Agente único GPT-4o | Agente único con búsqueda Google | Híbrido LLMs + Sonar |
| Tokens / Coste | 15× consumo ($3–75/1M) | 1× ($0.10–600/1M) | 20× más barato | Suscripción $20/mes |
| Latencia | 40–60 s tareas complejas | Sub-segundo | Rápida, optimizada | Variable |
| Trazabilidad | Citas verificables obligatorias | Opcional | Configurable | Parcial |
| Compliance | AI Act automático | Requiere configuración | Requiere configuración | Parcial |
1. Qué es Claude Research
1.1 Definición técnica y diferencial
Anthropic Claude Research es la funcionalidad de investigación profunda desarrollada por Anthropic que transforma la forma en que los LLM buscan, filtran y presentan información. A diferencia de Claude estándar, que responde con conocimiento pre-entrenado, Claude Research implementa un sistema multi-agente capaz de planificar, ejecutar y verificar procesos complejos con citas obligatorias.
👉 Diferencial clave: no es un chatbot genérico, sino una infraestructura de investigación trazable, diseñada para cumplir con marcos regulatorios exigentes como el AI Act europeo (2025).
1.2 Historia y contexto Anthropic
Anthropic fue fundada en 2021 por Dario y Daniela Amodei tras su salida de OpenAI. Se constituyó como Public Benefit Corporation (PBC) con un Long-Term Benefit Trust, garantizando que la prioridad fuera el desarrollo seguro y responsable frente al beneficio económico inmediato.
La compañía ha recibido inversiones masivas: Amazon ($8B) y Google ($2B), alcanzando una valoración de $61,5B en marzo 2025. Este respaldo financiero le permite sostener proyectos de largo plazo como Claude Research sin presiones comerciales inmediatas.
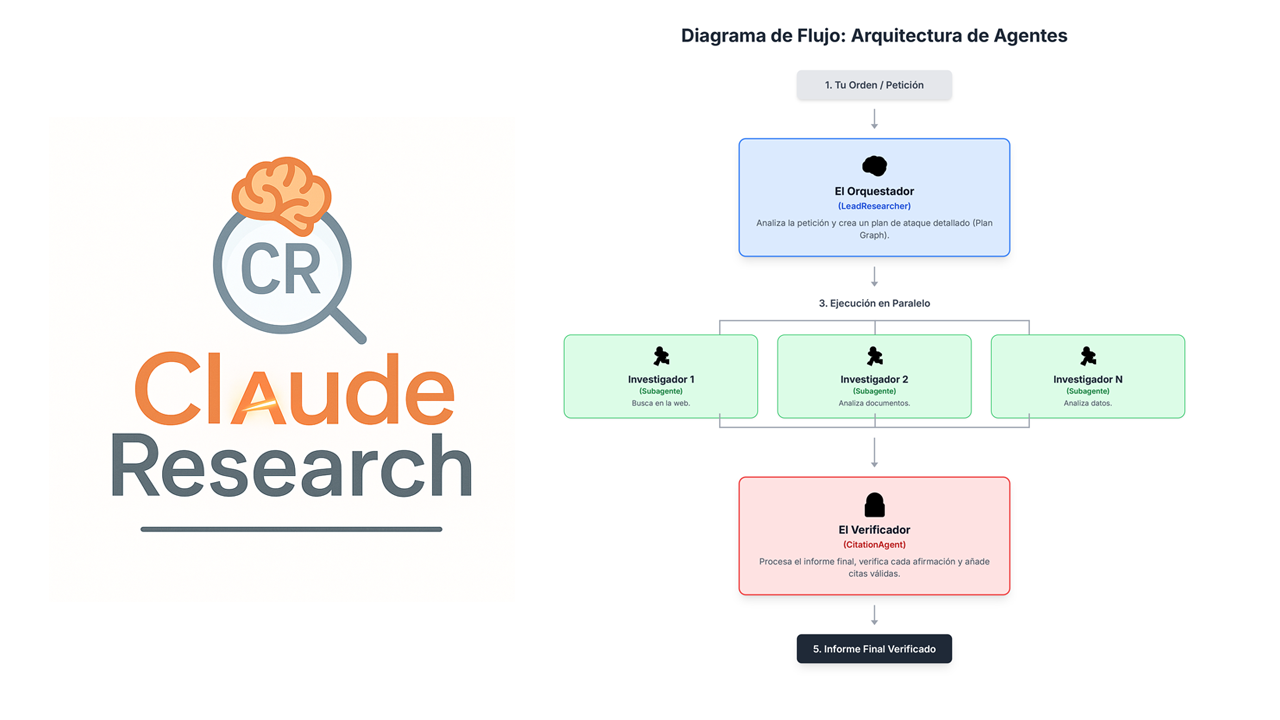
1.3 Arquitectura multi-agente
El sistema está compuesto por tres elementos principales:
- LeadResearcher (Claude Opus 4): orquestador que analiza la consulta, la descompone en subtareas y sintetiza resultados.
- Subagentes especializados (Claude Sonnet 4): ejecutan búsquedas paralelas en ventanas de contexto independientes de hasta 200K tokens.
- CitationAgent: asegura que cada afirmación tenga cita verificable (APA/MLA/Chicago) o se marque como [SIN CITA].
👉 Esto convierte a Claude Research en una especie de “equipo virtual de analistas junior”, donde cada agente tiene una función clara y supervisada.
1.4 Pipeline técnico
El flujo documentado sigue cuatro fases:
- Planificación: el LeadResearcher descompone la consulta y establece un plan de investigación persistente.
- Ejecución paralela: subagentes lanzan búsquedas simultáneas (web, Google Drive, etc.).
- Síntesis iterativa: el orquestador integra y depura resultados parciales.
- Citación especializada: el CitationAgent valida y añade trazabilidad completa.
Diagrama de arquitectura de agentes (Claude Research)
![Diagrama de la arquitectura de Claude Research: LeadResearcher orquesta a subagentes Sonnet (Búsqueda académica, Compliance, Benchmarking) hacia CitationAgent; salida con citas verificables o [SIN CITA].](https://delatorre.ai/wp-content/uploads/2025/09/pipline15.gif)
2. Por qué importa en 2025
2.1 Regulación: AI Act europeo
En agosto de 2025 entra en vigor el AI Act de la Unión Europea. Este marco regula los sistemas de alto riesgo y exige:
- Documentación técnica completa.
- Registros de capacidades, limitaciones y riesgos.
- Transparencia en datos y métodos.
Las sanciones por incumplimiento son severas: hasta €35 millones o 7% de la facturación global anual.
👉 Claude Research destaca porque cumple estas obligaciones de forma nativa. Su CitationAgent convierte cada salida en un documento auditable.
2.2 Crisis de transparencia en IA
Los sistemas de IA tradicionales tienen un problema crítico: generan texto convincente, pero sin fuentes claras.
- 64% de las organizaciones reconocen que no tienen visibilidad sobre los riesgos de sus sistemas IA.
- En investigación académica, 13,5% de los papers revisados en 2024–2025 mostraban contenido de LLM sin citar adecuadamente.
- La reproducibilidad se degrada: es difícil replicar resultados sin documentación de fuentes.
👉 Aquí Claude Research aporta valor: cada afirmación debe ir acompañada de cita verificable o de la marca [SIN CITA].
2.3 Adopción empresarial acelerada
Los datos más citados y su fuente exacta:
- 78% de las organizaciones declara usar IA (analítica + genAI) en al menos una función. Fuente: McKinsey — The State of AI (Global survey)
- El gasto empresarial en IA generativa alcanzó $13.8 mil millones en 2024 (≈6× vs 2023). Fuente: Menlo Ventures — 2024: The State of Generative AI in the Enterprise
- 49% de CIOs afirma que la IA está plenamente integrada en la estrategia core de su compañía.Fuente: PwC Pulse Survey (Oct 15, 2024)
👉 En este escenario, la trazabilidad deja de ser opcional y se convierte en ventaja competitiva.
2.4 Oportunidad en mercados hispanohablantes
- Mercado en expansión: La IA en América Latina se valoró en $4,71 mil millones (2024) y apunta a $30,20 mil millones en 2033 (CAGR 22,9%). Fuente: IMARC Group — Latin America Artificial Intelligence Market
- Liderazgo regional (foco hispanohablante): El ILIA 2024 sitúa a Chile (73,07) como líder; Uruguay (64,98) y Argentina (55,77) avanzan como adoptantes, mientras Brasil (69,30) es segundo y motor regional. Fuentes: CEPAL — Comunicado ILIA 2024 y ILIA 2024 — Informe completo (PDF)
- Brasil concentra ≈38,2% del submercado LATAM de datasets de entrenamiento de IA (2023) — no es el “mercado total de IA”, sino un segmento. Fuente: Credence Research — LATAM AI Training Datasets Market
👉 Oportunidad clara para soluciones trazables y auditables (registro de prompts/datos/modelos, controles de riesgo, evidencias de cumplimiento).
2.5 Importancia del momentum 2025
Momentum 2025
AI Act (UE) — Línea de tiempo
- Transparencia & trazabilidad obligatorias (documentación técnica, registros de capacidades/limitaciones, fuentes de datos).
- Agosto 2025: entrada en aplicación completa para sistemas de alto riesgo.
- Sanciones: hasta €35M o 7% del volumen global anual.
- Supervisión: Oficina Europea de IA y autoridades competentes.
LatAm IA — Proyección de mercado
$4,71 mil millones
$30,20 mil millones
CAGR 22,9% (2024→2033). Oportunidad: soluciones trazables y auditables para sectores regulados.
- ILIA 2024: Chile 73,07 · Brasil 69,30 · Uruguay 64,98 · Argentina 55,77.
- Brecha de gobernanza: baja adopción de marcos oficiales → ventana B2B para compliance.
Fuentes en insumos del proyecto: AI Act (obligaciones, sanciones) y cifras LatAm ($4,71B → $30,20B; CAGR 22,9%).
3. Cómo aplicarlo paso a paso (Método JL adaptado)
3.1 Tratarlo como “analista júnior”
Claude Research no es un sustituto de criterio humano. Piénsalo como un analista junior:
- Aporta volumen y velocidad.
- Requiere supervisión senior.
- Nunca debe usarse como única fuente en decisiones críticas.
👉 Principio clave: Human-in-the-Loop (HITL).
3.2 Marco ≤7 subtareas
El Método JL recomienda un máximo de 7 subtareas por investigación:
- Evita sobrecarga cognitiva.
- Reduce proliferación de subagentes (análisis multi-agente, arXiv).
- Facilita verificación cruzada.
Ejemplo: Objetivo → Subtareas → Fuentes → Formato → Exclusiones.
3.3 Checklist de calidad (7 pasos)
Bloque práctico — cada investigación con Claude Research debe pasar por este filtro:
- Definición de objetivo
- SMART, claro y acotado.
- Estructuración de consulta
- ≤7 subtareas, no solapadas.
- Ejecución y monitoreo
- Vigilar consumo tokens y latencia.
- Verificación cruzada
- Fact-checking y detección [SIN CITA].
- Síntesis y análisis
- Responder al objetivo inicial, con límites explícitos.
- Documentación de compliance
- Registrar prompts, versiones y fuentes.
- Revisión final humana
- Validación senior antes de uso ejecutivo.
3.4 Regla [SIN CITA]
Si una afirmación no tiene fuente verificable → marcar como [SIN CITA].
- Aumenta la transparencia.
- Evita outputs que parecen “seguros” pero carecen de respaldo.
Checklist Claude Research – Método JL (7 pasos)

Visual integrado del checklist (descargable). Si tu navegador no muestra PDFs, usa los botones debajo.
📥 Descargar Demo GRATUITA (10′)
Incluye tabla FLOJO vs ESTRUCTURADO + checklist Método JL.
4. Comparativa con alternativas
4.1 Claude Research vs ChatGPT ADA
- Claude Research: multi-agente (Opus + Sonnet + CitationAgent), trazabilidad obligatoria, contexto hasta 1M tokens.
- ChatGPT ADA (GPT-4o): agente único, integrado con Code Interpreter y 128K tokens, más rápido (sub-segundo) y económico (suscripción mensual).
👉 Cuándo usar cada uno: - Claude para compliance y proyectos auditables.
- ChatGPT para exploración rápida, workflows y prototipado Fuente oficial: Anthropic — Research.
4.2 Claude Research vs Gemini Deep Research
- Claude Research: diseñado para trazabilidad y compliance AI Act.
- Gemini Deep Research: acceso nativo a Google Search, contexto extendido (1M tokens), multimodal (texto + imágenes + vídeo), 20× más barato.
👉 Trade-off: Gemini gana en coste y velocidad; Claude en compliance automático y trazabilidad nativa.
4.3 Claude Research vs frameworks open-source
- Langroid: paradigma multi-agente open source, flexible y transparente.
- AgentScope: escalabilidad masiva (hasta 1M agentes), pero curva de aprendizaje alta.
- AutoGen: event-driven, cross-language, comunidad GitHub activa.
👉 Claude Research: solución lista para empresas, con soporte y compliance nativo.
👉 Open-source: control total, menor coste si hay expertise técnica, pero mayor complejidad.
4.4 Tabla comparativa clave
| Dimensión | Claude Research | ChatGPT ADA | Gemini Deep Research | Open-Source (Langroid/AgentScope) |
| Arquitectura | Multi-agente (Opus+Sonnet+Citation) | Agente único GPT-4o | Agente único + Google Search | Multi-agente personalizable |
| Coste/Tokens | 15–26× más caro ($3–75/1M) | $20/mes Plus | 20× más barato | Optimizable (depende infra) |
| Latencia | 40–60 s tareas complejas | Sub-segundo | Optimizada velocidad | Variable (infra propia) |
| Contexto | 200K–1M tokens | 128K tokens | 1M tokens | Configurable |
| Trazabilidad | Obligatoria ([SIN CITA]) | Opcional | Parcial | Total (depende configuración) |
| Compliance | AI Act automático | Requiere configuración | Requiere configuración | Depende equipo técnico |
Matriz semáforo — Fortalezas y debilidades por dimensión
Verde = Fortaleza
Amarillo = Aceptable / Trade-off
Rojo = Debilidad / Riesgo
Clasificación cualitativa basada en el apartado 4.4 del artículo. Si alguna dimensión requiere evidencia puntual, marcar [SIN CITA] hasta confirmación.
25 prompts estructurados + Flight Manual + Checklist + SystemCard JL.
5. Casos de uso sectoriales
5.1 Compliance regulatorio
- KYC/AML: validación de identidades y detección de transacciones sospechosas.
- ISO/IEC 27002: generación de dashboards de cumplimiento en minutos.
- AI Act: descomposición de regulaciones en obligaciones discretas.
👉 Beneficio: reduce riesgo de sanciones y asegura trazabilidad.
5.2 Educación superior
Usado en universidades para revisiones sistemáticas de literatura y guías docentes:
- Rapidez en detectar fuentes relevantes.
- Síntesis de acuerdos entre papers.
- Limitaciones: citas incompletas, riesgo de “alucinación académica” si no hay revisión humana.
👉 Beneficio: soporte para investigación y docencia, siempre bajo supervisión académica.
5.3 Fintech y seguros
Casos reales:
- Arc Technologies: análisis financiero complejo con Claude Opus 4.
- Snorkel Seguros: evaluación de riesgos mejor que otros modelos.
- M1 Finance: fallo crítico al inventar columnas SQL inexistentes.
👉 Beneficio: potencia en benchmarking y gestión de riesgos, pero exige validación técnica.
5.4 Otros sectores con potencial
- Agritech (Brasil): IA en agricultura de precisión (30% del PIB).
- Healthcare: detección temprana de tumores con 90% de precisión.
- Gobiernos: elaboración de cronologías regulatorias y políticas públicas.
👉 Brecha: solo 17% de empresas LatAm tienen marcos de gobernanza IA.
5.5 Matriz sector × valor × riesgo
| Sector | Valor estratégico | Riesgo principal | Notas |
| Compliance | Alto (AI Act, KYC/AML) | Costes ×15 y bucles infinitos | Justifica inversión en trazabilidad |
| Educación | Medio-alto (síntesis) | Citas incompletas, alucinaciones | Requiere HITL académico |
| Fintech | Muy alto (benchmark) | SQL inventado, decisiones críticas | Validación schema obligatoria |
| Healthcare | Alto (diagnóstico) | Riesgo ético-regulatorio | Complemento a revisión médica |
| Agritech | Medio (eficiencia) | Dependencia de datos locales | Caso LatAm creciente |
Matriz Valor vs Riesgo — Casos de uso Claude Research
Posicionamiento estimado según 5.5 Matriz sector × valor × riesgo del artículo (alto = arriba; riesgo alto = derecha).
Ajusta posiciones si cambian las notas del apartado 5.5. Mantén HITL y la regla [SIN CITA] donde no haya evidencia.
6. Errores comunes y cómo evitarlos
Prompts vagos
- Qué ocurre: generan 50+ subagentes innecesarios, consumo descontrolado de tokens.
- Ejemplo real: prompt genérico “Agrega pruebas para foo.py” produjo loops redundantes.
- Cómo evitarlo: usar prompts estructurados (objetivo SMART, ≤7 subtareas, exclusiones claras).
Thin content
- Qué ocurre: reportes de 40+ páginas con citas, pero poco accionables (galimatías corporativo).
- Ejemplo real: Claude Research vs Gemini → Gemini más conciso, Claude excesivamente verboso.
- Cómo evitarlo: checklist de calidad JL (síntesis clara, recomendaciones específicas).
Bucles infinitos
- Qué ocurre: el sistema queda atascado repitiendo instrucciones, consumiendo miles de tokens. … consumiendo miles de tokens. Ver también arXiv (fallos en sistemas multi-agente).
- Ejemplo real: Claude Code 1.0.83+ ejecutó 900+ comandos “echo” idénticos en segundos.
- Cómo evitarlo: monitoreo activo de tokens y circuit breakers (límites por sesión).
SQL alucinatorio
- Qué ocurre: inventa columnas o tablas que parecen correctas pero no existen.
- Ejemplo real: M1 Finance implementó consultas SQL con errores críticos no detectados.
- Cómo evitarlo: validación automática de schema antes de ejecutar queries.
Subestimar costes
- Qué ocurre: en casos extremos, Claude Research ha generado $16k–50k en 5 horas.
- Cómo evitarlo: establecer alertas de consumo y pilotos de 6 meses antes de escalar.
Visual recomendado
Errores comunes y cómo evitarlos — Warning cards
⚠️ Prompts vagos
Qué ocurre: generan 50+ subagentes innecesarios y consumo descontrolado de tokens.
Ejemplo real: prompt genérico “Agrega pruebas para foo.py” produjo loops redundantes. [SIN CITA]
Cómo evitarlo:
- Usar objetivo SMART y ≤7 subtareas.
- Definir exclusiones y formato de salida.
- Revisar consumo de tokens por subtarea.
⚠️ Thin content
Qué ocurre: reportes de 40+ páginas con citas pero poco accionables.
Ejemplo real: comparativas extensas que no aterrizan en decisiones. [SIN CITA]
Cómo evitarlo:
- Aplicar checklist JL (síntesis + recomendaciones concretas).
- Limitar a hallazgos clave y tabla accionable.
- Validar que cada sección responda al objetivo nuclear.
🛑 Bucles infinitos
Qué ocurre: el sistema repite instrucciones, consumiendo miles de tokens.
Ejemplo real: Claude Code 1.0.83+ ejecutó 900+ comandos “echo” idénticos en segundos. [SIN CITA]
Ver también arXiv (fallos en sistemas multi-agente).
Cómo evitarlo:
- Monitoreo activo de tokens/sesión.
- Circuit breakers (límites por tiempo y consumo).
- Revisión humana al detectar patrones repetitivos.
🛑 SQL alucinatorio
Qué ocurre: inventa columnas o tablas que parecen válidas pero no existen.
Ejemplo real: caso M1 Finance con consultas SQL erróneas no detectadas. [SIN CITA]
Cómo evitarlo:
- Validación automática de schema antes de ejecutar.
- Pruebas con datasets sintéticos y tipado.
- Revisión de consultas generadas por un analista.
⚠️ Subestimar costes
Qué ocurre: en casos extremos, una sesión puede dispararse a $16k–$50k en 5 horas. [SIN CITA]
Cómo evitarlo:
- Alertas de consumo y presupuesto por sesión.
- Piloto 6 meses antes de escalar.
- Limitar subagentes y duración (≤45 min).
💡 Evita estos errores con el
Checklist de Pre-vuelo (FREE)
y los
25 Prompts del Pack LITE (29 €).
7. Módulo: Metodología y Citación
7.1 Principios del Método JL
![Captura de Claude Research con la pauta del Método JL: ≤7 subtareas, formato fijo, regla [SIN CITA], fecha mínima 2024-01-01 y fuentes (Anthropic, OpenAI, DeepMind, arXiv…).](https://delatorre.ai/wp-content/uploads/2025/09/Captura-de-pantalla-2025-09-01-033705.png)
- Rol definido: el modelo actúa como analista júnior, nunca como decisor.
- Objetivo nuclear: 1 meta central bien acotada.
- ≤7 subtareas: dividir la consulta en partes independientes y manejables.
- Formato fijo: mini-brief, tabla, cronología o matriz de decisión.
- Citas verificables: toda afirmación requiere fuente o se marca como [SIN CITA].
7.2 Uso obligatorio de [SIN CITA]
La etiqueta [SIN CITA] es un estándar del método:
- Marca transparencia en la salida.
- Evita “alucinaciones” con tono de certeza sin respaldo.
- Aumenta confianza y facilita revisiones.
7.3 Aplicación en FREE y LITE
- FREE: demostración rápida (prompt maestro, tabla FLOJO vs ESTRUCTURADO, checklist).
- LITE (29 €): ejecución completa con SystemCard JL v1.4, Flight Manual y 25 prompts estructurados.
👉 Ambos incluyen este módulo de citación como regla de oro.
Módulo: Metodología y Citación — Método JL
Ambos incluyen este módulo de citación como regla de oro.
8. FAQ
¿Qué es Claude Research y cómo funciona?
Es la versión de investigación profunda de Anthropic. Usa un sistema multi-agente (Opus + Sonnet + CitationAgent) que planifica, ejecuta y cita resultados de forma verificable. Se diferencia de un chatbot genérico porque cada salida está diseñada para ser auditable.
¿Cuánto cuesta una investigación (tokens)?
Claude Research consume 15× más tokens que un chat estándar. Según el plan, puede costar entre $3 y $75 por millón de tokens, con casos extremos documentados de $16k–50k en 5 horas sin control de consumo.
¿Cómo citar resultados de IA?
El método obliga a marcar cada afirmación con fuente verificable o la etiqueta [SIN CITA]. Las citas pueden seguir formatos APA, MLA o Chicago, y siempre deben verificarse en la fuente original.
¿Qué limitaciones técnicas tiene Claude Research?
- Latencia: 40–60 segundos en tareas complejas.
- Sesiones máximas: 45 minutos.
- Riesgos: bucles infinitos, citas incompletas, SQL alucinatorio.
👉 Requiere supervisión humana y checklist de calidad.
¿Vale para startups o solo grandes empresas?
Claude Research justifica su coste en sectores regulados (fintech, salud, compliance). Para usos generales, herramientas como Gemini o Perplexity pueden ser más económicas. Pero si la prioridad es trazabilidad y AI Act, Claude es la mejor opción.
9. CTAs finales y cierre
📦 Elige tu versión y empieza hoy mismo
| Características | FREE (demo) | LITE (29 €) |
|---|---|---|
| Prompt maestro | ✅ | ✅ |
| Checklist | Básico | Avanzado |
| Comparativa FLOJO/ESTRUCTURADO | ✅ | ✅ |
| 25 Prompts sectoriales | ❌ | ✅ |
| Flight Manual + SystemCard JL | ❌ | ✅ |
📊 FREE vs LITE
| Característica | FREE (demo) | LITE (29 €) |
| Prompt maestro | ✅ | ✅ |
| Checklist básico | ✅ | ✅ Avanzado |
| Comparativa FLOJO/ESTRUCT. | ✅ | ✅ |
| 25 Prompts por sector | ❌ | ✅ |
| Flight Manual | ❌ | ✅ |
| SystemCard JL | ❌ | ✅ |
🔗 Enlazado interno